
[1]:
%run notebook_setup
If you have not already read it, you may want to start with the first tutorial: Getting started with The Joker.
Inferring calibration offsets between instruments#
Also in addition to the default linear parameters (see Tutorial 1, or the documentation for JokerSamples.default()), The Joker allows adding linear parameters to account for possible calibration offsets between instruments. For example, there may be an absolute velocity offset between two spectrographs. Below we will demonstrate how to simultaneously infer and marginalize over a constant velocity offset between two simulated surveys of the same “star”.
First, some imports we will need later:
[2]:
import astropy.table as at
import astropy.units as u
import numpy as np
import corner
import pymc as pm
import thejoker.units as xu
import arviz as az
import thejoker as tj
%matplotlib inline
WARNING (pytensor.tensor.blas): Using NumPy C-API based implementation for BLAS functions.
[3]:
# set up a random number generator to ensure reproducibility
rnd = np.random.default_rng(seed=42)
The data for our two surveys are stored in two separate CSV files included with the documentation. We will load separate RVData instances for the two data sets and append these objects to a list of datasets:
[4]:
data = []
for filename in ["data-survey1.ecsv", "data-survey2.ecsv"]:
tbl = at.QTable.read(filename)
_data = tj.RVData.guess_from_table(tbl, t_ref=tbl.meta["t_ref"])
data.append(_data)
In the plot below, the two data sets are shown in different colors:
[5]:
for d, color in zip(data, ["tab:blue", "tab:red"]):
_ = d.plot(color=color)
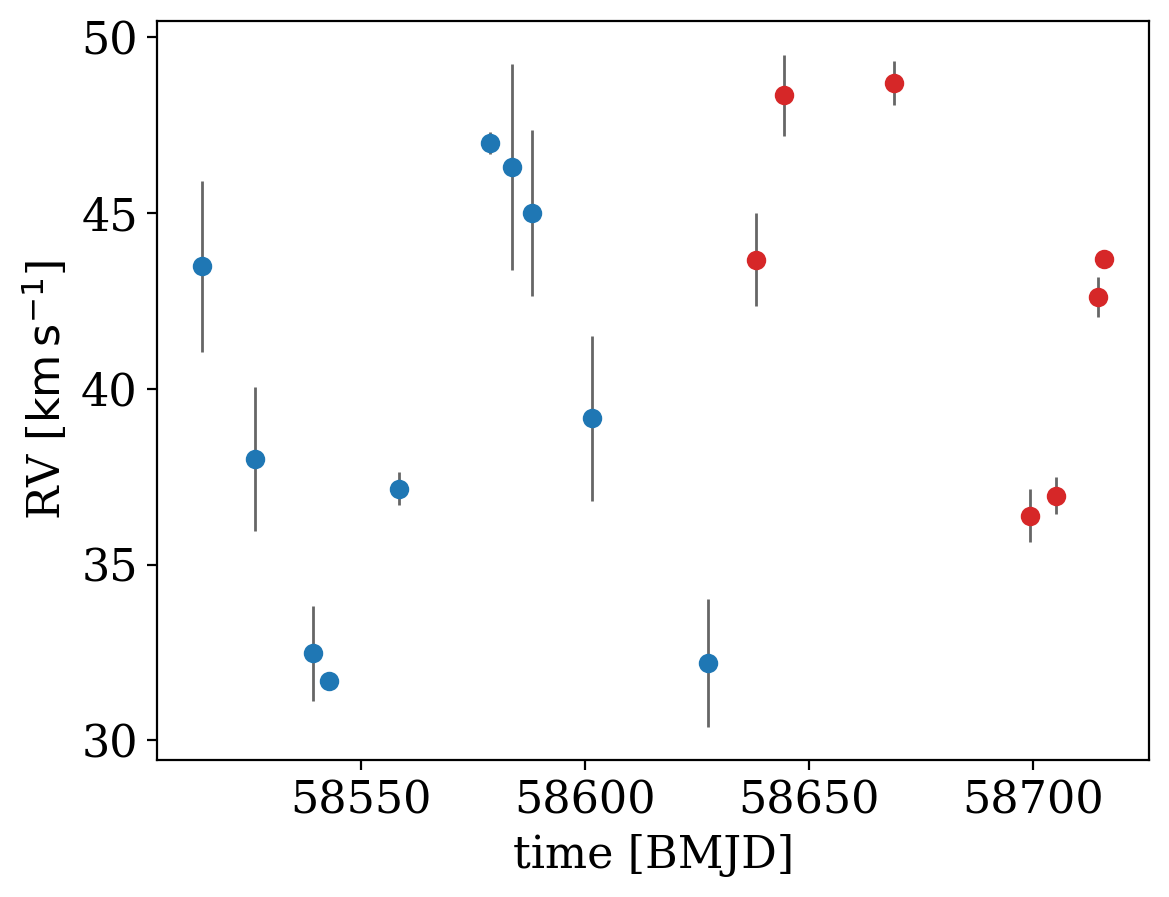
To tell The Joker to handle additional linear parameters to account for offsets in absolute velocity, we must define a new parameter for the offset betwen survey 1 and survey 2 and specify a prior. Here we will assume a Gaussian prior on the offset, centered on 0, but with a 10 km/s standard deviation. We then pass this in to JokerPrior.default() (all other parameters here use the default prior) through the v0_offsets argument:
[6]:
with pm.Model() as model:
dv0_1 = xu.with_unit(pm.Normal("dv0_1", 0, 10), u.km / u.s)
prior = tj.JokerPrior.default(
P_min=2 * u.day,
P_max=256 * u.day,
sigma_K0=30 * u.km / u.s,
sigma_v=100 * u.km / u.s,
v0_offsets=[dv0_1],
)
The rest should look familiar: The code below is identical to previous tutorials, in which we generate prior samples and then rejection sample with The Joker:
[7]:
prior_samples = prior.sample(size=1_000_000, rng=rnd)
[8]:
joker = tj.TheJoker(prior, rng=rnd)
joker_samples = joker.rejection_sample(data, prior_samples, max_posterior_samples=128)
joker_samples
[8]:
<JokerSamples [P, e, omega, M0, s, K, v0, dv0_1] (5 samples)>
Note that the new parameter, dv0_1, now appears in the returned samples above.
If we pass these samples in to the plot_rv_curves function, the data from other surveys is, by default, shifted by the mean value of the offset before plotting:
[9]:
_ = tj.plot_rv_curves(joker_samples, data=data)
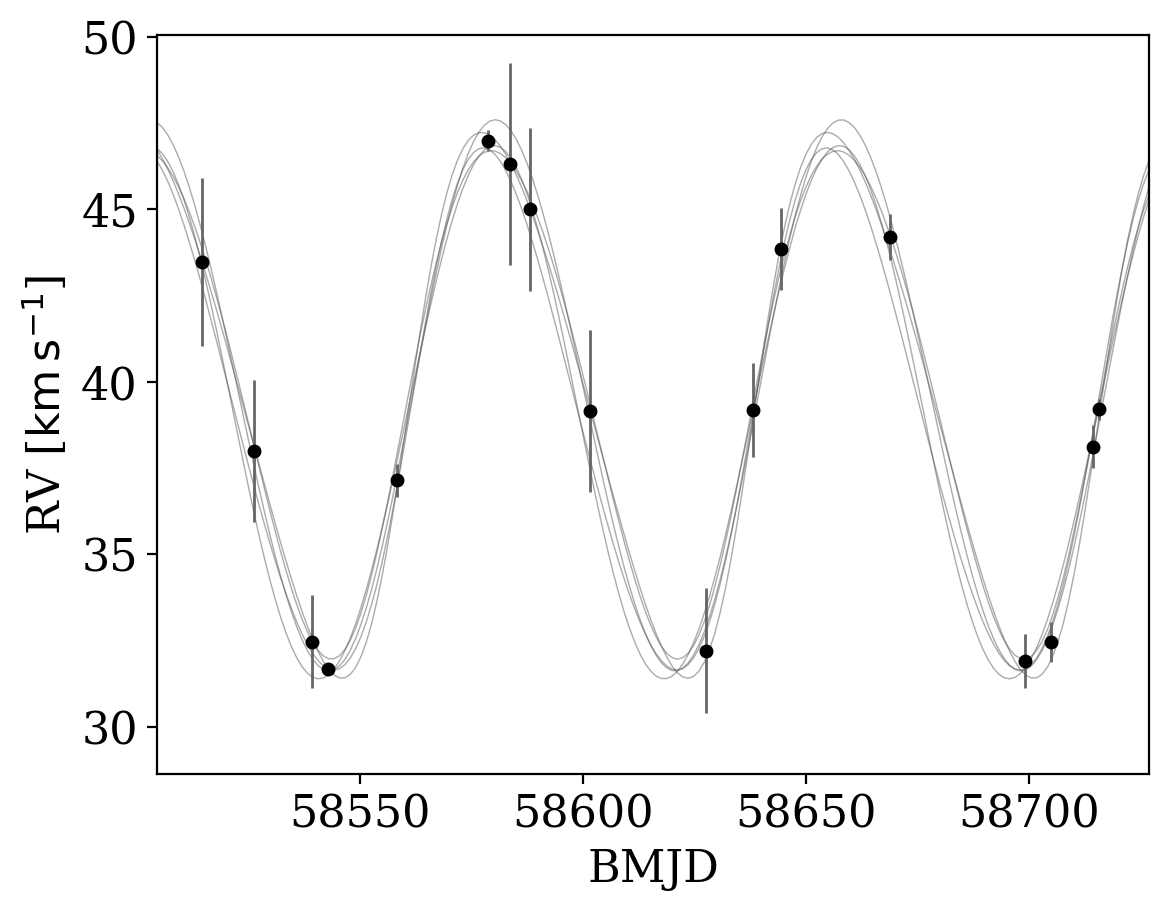
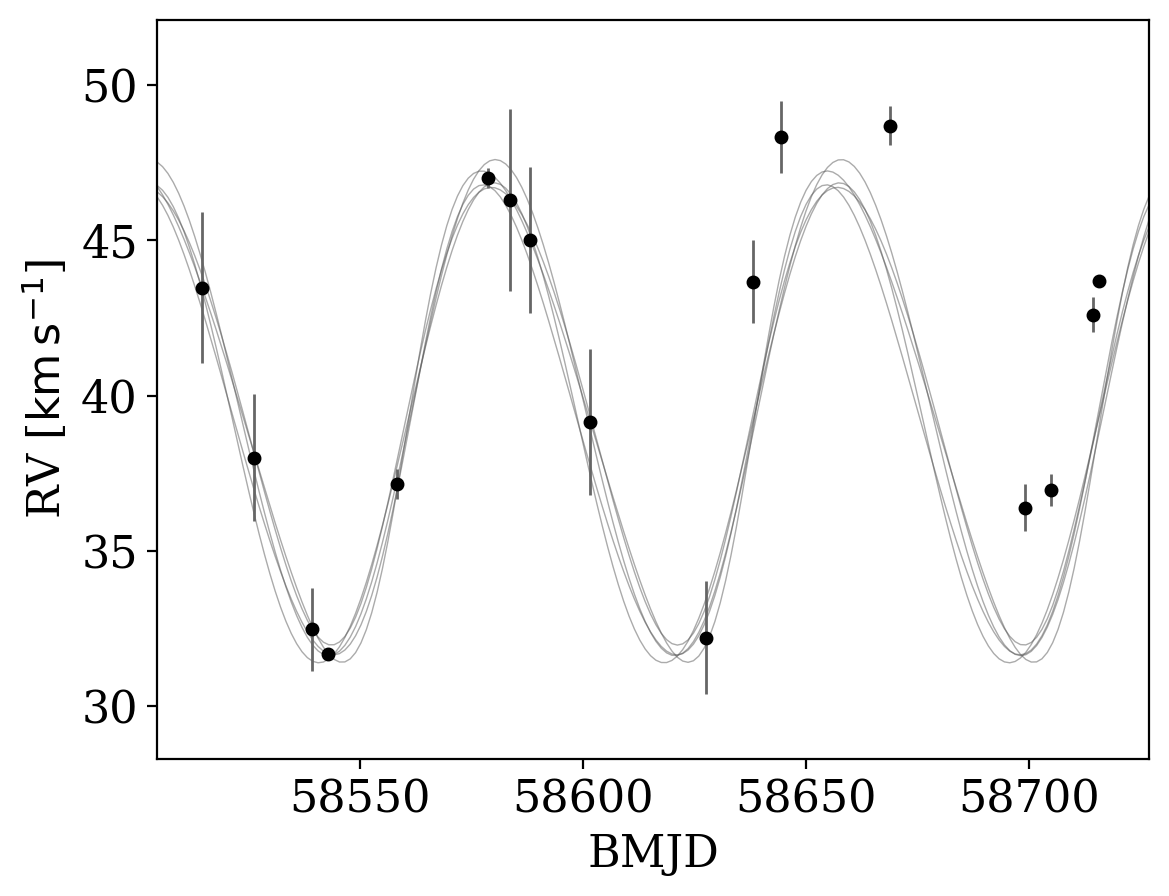
However, the above behavior can be disabled by setting apply_mean_v0_offset=False. Note that with this set, the inferred orbit will not generally pass through data that suffer from a measurable offset:
[10]:
_ = tj.plot_rv_curves(joker_samples, data=data, apply_mean_v0_offset=False)
As introduced in the previous tutorial, we can also continue generating samples by initializing and running standard MCMC:
[11]:
with prior.model:
mcmc_init = joker.setup_mcmc(data, joker_samples)
trace = pm.sample(tune=500, draws=500, start=mcmc_init, cores=1, chains=2)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Sequential sampling (2 chains in 1 job)
NUTS: [dv0_1, e, __omega_angle1, __omega_angle2, __M0_angle1, __M0_angle2, P, K, v0]
/opt/hostedtoolcache/Python/3.11.9/x64/lib/python3.11/site-packages/rich/live.py:231: UserWarning: install
"ipywidgets" for Jupyter support
warnings.warn('install "ipywidgets" for Jupyter support')
Sampling 2 chains for 500 tune and 500 draw iterations (1_000 + 1_000 draws total) took 57 seconds.
We recommend running at least 4 chains for robust computation of convergence diagnostics
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
[12]:
az.summary(trace, var_names=prior.par_names)
/opt/hostedtoolcache/Python/3.11.9/x64/lib/python3.11/site-packages/arviz/stats/diagnostics.py:596: RuntimeWarning: invalid value encountered in scalar divide
(between_chain_variance / within_chain_variance + num_samples - 1) / (num_samples)
[12]:
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| P | 76.914 | 0.532 | 75.924 | 77.890 | 0.032 | 0.023 | 276.0 | 347.0 | 1.00 |
| e | 0.054 | 0.044 | 0.000 | 0.131 | 0.003 | 0.002 | 204.0 | 452.0 | 1.00 |
| omega | 0.683 | 1.438 | -2.303 | 3.104 | 0.116 | 0.094 | 197.0 | 174.0 | 1.01 |
| M0 | -0.783 | 2.176 | -3.085 | 3.011 | 0.156 | 0.145 | 251.0 | 451.0 | 1.01 |
| s | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 1000.0 | 1000.0 | NaN |
| K | -7.754 | 0.169 | -8.064 | -7.434 | 0.010 | 0.007 | 285.0 | 346.0 | 1.00 |
| v0 | 39.487 | 0.243 | 39.037 | 39.933 | 0.015 | 0.011 | 296.0 | 164.0 | 1.01 |
| dv0_1 | 4.282 | 0.455 | 3.413 | 5.169 | 0.028 | 0.020 | 266.0 | 495.0 | 1.00 |
Here the true offset is 4.8 km/s, so it looks like we recover this value!
A full corner plot of the MCMC samples:
[13]:
mcmc_samples = tj.JokerSamples.from_inference_data(prior, trace, data)
mcmc_samples = mcmc_samples.wrap_K()
[14]:
df = mcmc_samples.tbl.to_pandas()
colnames = mcmc_samples.par_names
colnames.pop(colnames.index("s"))
_ = corner.corner(df[colnames])
WARNING:root:Pandas support in corner is deprecated; use ArviZ directly
